Exciting news: you can now listen to talk about my latest project -- What Products Bring Us Joy?-- on YouTube!
Stay tuned for more data science projects to come! I have a few ideas I'm playing with.
|
|
|
Exciting news: you can now listen to talk about my latest project -- What Products Bring Us Joy?-- on YouTube!
Stay tuned for more data science projects to come! I have a few ideas I'm playing with.
0 Comments
Consumerism, in general, fascinates me. I'm always curious how people engage with products and the emotional valence behind those interactions. What about an object makes us actually feel something? Why and how is this important? There's a lot of recent research indicating that we get more long-term joy out of experiences than we do from objects. At the same time, Marie Kondo has been wildly popular as of late, and her insinuation is that some objects do in fact spark joy. Not all of them, of course, but there are certainly some objects that we want to keep around. Ingrid Fetell Lee has a blog and recently wrote a popular book detailing characteristics of objects that bring us joy, such as color and shape. Given this contrast, how can we better understand what products actually do cause joy rather than (or even, perhaps, in addition to) gather dust?  Data and ProcessIn order to address these questions, I analyzed 450 thousand Amazon product reviews. Tools I used included:
Through using tone analysis, I was able to label each review with a score for joyfulness as well as for several other emotional metrics. I chose k-means clustering because this method made the most sense of my data. I came up with 8 clusters because this number both minimized inertia and was interpretable. What Categories of Products Bring Happiness?I was able to isolate a few categories wherein the reviews had higher joy ratings on average and a few categories that had lower joy ratings on average:  How might we interpret this? The more joyful categories are actually products that tend to be more experiential while the less joyful categories are more practical or functional. This aligns nicely with prevailing research about experiences bringing more long-term joy than possessions. Relationship Between Star Rating and JoyOk, great. But-- I bet you're wondering about the one to five star rating that reviewers give a product. Interestingly enough, there is...  What this might mean is that joy is actually a separate metric from star rating. It's pretty common to use star rating as a measure of customer satisfaction, and it is, but this analysis would indicate that it is not the only viable or interesting measure. So what's the difference between them? Let's look at four categories: 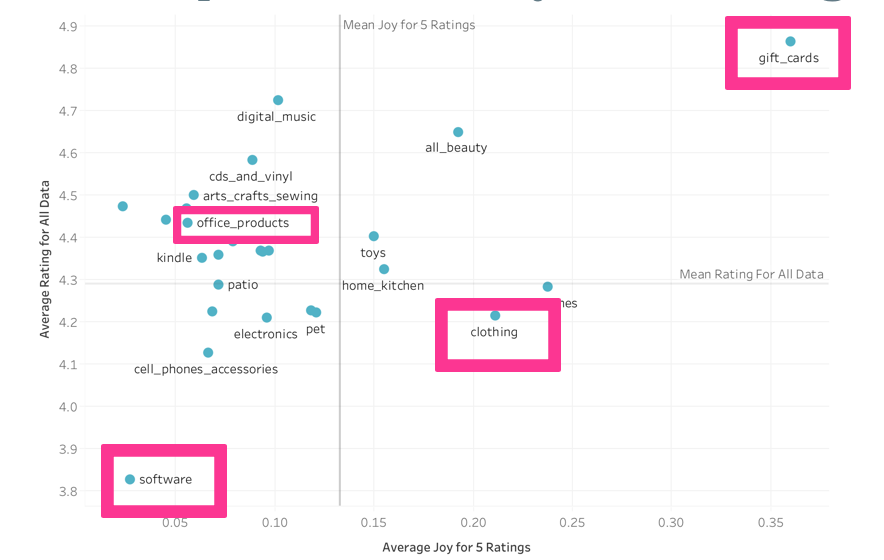 In this figure, average rating for all data is on the y axis and average joy score for ratings with five stars is on the x axis. (As indicated by the lack of correlation, categories had similar average joy scores regardless of rating). First let’s start with gift cards— they’re high on both average joy and average rating. What I think this means is that people enjoy the experience of giving, the act of it, but also, they know exactly what the product is— their expectations are met, which I think is what the rating reflects. Office products are relatively high on rating, but low on joy, illustrating that people are getting the function they expect (hence the rating), but they might not be optimizing for the experience. For clothing, people are very joyful, probably because they get to wear something new and experience the item very viscerally, but the ratings are a bit low— we often order clothing items and they’re not really what we expected them to be (or at least that often happens to me!). And finally, software is low on joy and on rating, which means that the software might not be exactly what we expected and, also, we are not enjoying the experience of using it too much. So we’ve examined joy by category, but taking category out of the equation, how can we group products agnostic of category and, then, how can we see which products are joyful? What Products Bring Happiness Agnostic of Category?In order to investigate this question, I used PCA and clustered products. My algorithm came up with eight clusters which I've labeled:
As you can see, my clusters are themselves clustered by gradation: the relatively happy reviews, neutral reviews, and unhappy reviews. Also worth noting is that this analysis was done on five star reviews, so there were less joyful sentiments even about products that were rated highly. In order to delve further into what these clusters might indicate, I wanted to compare a couple reviews from the sad cluster (leaving aside the sad and disgusted cluster, which is getting at a bit of a different construct) and the very joyful cluster.  How can we summarize these reviews? For the sad cluster, these reviews basically say "This thing did what I wanted it to do and there is nothing special about it." On the other hand, for very joyful cluster, the reviews say "This thing made me feel and experience in a different way." In the second review for the very joyful cluster, the reviewers are discussing a plug, but there is something about the design of it, the experience of using it, and, in this case, I would assume the convenience of it, that is getting them all excited about the product to the point that they would actually recommend it to others. One thing we can see here, beyond the fact that experience of a product seems to be at play, is that said experience is also informed by certain components of product design and the ways in which users engage with a product. A Word on Seasonality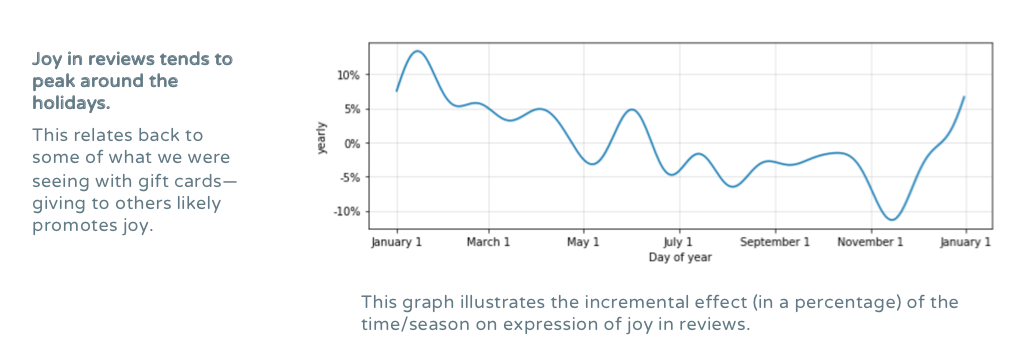 It appears that there is a certain confluence between giving and customer satisfaction as measured through joy. Preliminary topic modeling on reviews also indicated that the very joyful cluster had more language related to giving. The further implication here is that what a customer actually does with a product matters. It's not just about the function that that product itself has, but about the emotional function the product has for the purchaser. So What? Why is This Important?Understanding consumer satisfaction using data that were not directly solicited from customers through surveys can inform UX research, can influence product design, and can contribute to crafting a more robust consumer strategy. Consumer satisfaction can have all kinds of positive externalities for word-of-mouth advertising, brand image, and even repurchase behavior. More broadly, the techniques I've illustrated here have broad business applications beyond this context and are likely to add value to any analytic process.  Finally it had come: the project were we were going to use natural language processing (NLP) and I knew I wanted to do something a bit out of the box. My PhD involved a fair amount of moral psychology work and thinking about what others take offense to cross-culturally. We know some basic things: pretty much every culture is appalled by incest, for example. But what else could we find out? Because I also worked (in various capacities) at UChicago's Booth School of Business, I knew that teaching soft skills is a serious priority. How can we best get along with others and make sure that group work flows smoothly? Being able to predict when others think we have crossed a line, or better understanding how they might react to our behavior more broadly, could help us to have more fruitful interactions with each other, leading, potentially, to more productivity within business contexts. Where might I find narratives detailing a moment when someone was unsure of what was his fault? Where could I find crowdsourced determinations of whether that person was at fault? REDDIT! In this project, I sought to answer three questions: 1. Under what circumstances are people unsure of whether they’re at fault? 2. How do others respond to those narratives? 3. Can we predict whom others will find at fault? The DataMy data were from a subreddit called Am I the Asshole? or AITA. This subreddit is often the butt of many a pop culture joke, which gave me all the more reason to take it seriously as a thing to analyze and make sense of.  Using the Reddit API, I was able to gather around 800 posts and their comments from AITA. I stored these data in MongoDB. 1. When Are We Unsure of Fault?To answer my first question, I used topic modeling on all of the posts I had. I ended up using a non-negative matrix factorization (NMF) model with a term frequency-inverse document frequency (TF-IDF) matrix. So what topics came up? 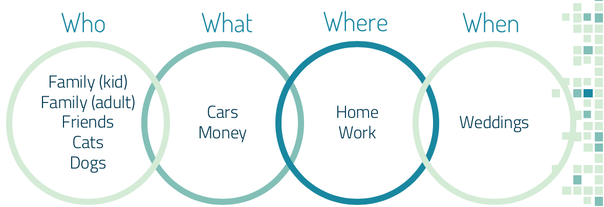 It's interesting to note here is that family (kid) means that you’re the child in the family, family (adult) means that you’re the adult in the family. Which topics were discussed the most? 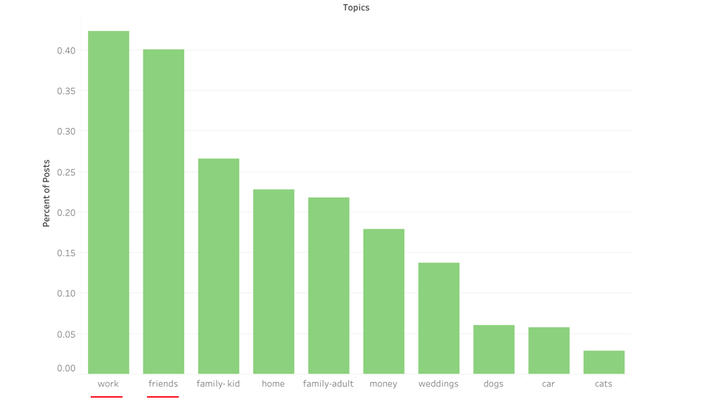 People seem to talk most about work and friends. This makes sense: these are situations where the impression you make likely matters to you. There is a middle level of closeness, as opposed to family who are stuck with you and people you might meet in passing, whom you won’t see again. Instead, these middling levels of knowing someone lead to more need for image management, implying a potentially greater likelihood to second guess one's own behavior. 2. How Do Others Respond?Though people talked the most about work and friends, the most commented-upon topic was, by far, family where the writer is the adult. Secondarily, people also like to comment on posts about weddings and posts related to family where the writer is the child. What this possibly means is that other people really have opinions on how one should run one’s family, but people are somewhat less worried about how their actions will be received in their own families. When we tell narratives about our own families, we might not expect that others are evaluating our behavior, but, in fact, they are. Something nice here, though, is that while you might be very worried about how your friends and colleagues perceive you and your actions with them, it's possible that they're not really all that worried about it. Another really nice finding is that the more positive we are, the more positive others are in response:  I used TextBlob and IBM Watson's Tone Analyzer to get sentiment (positive, negative) and tone (a range of emotions) for each review. What I found is that peoples' sentiment actually mimic's the sentiment of the post they're responding to. There's been a lot of research on how humans mirror each other-- usually in person-- but this is preliminary evidence that mirroring is occurring both in terms of sentiment and via written text. Practically, this is really interesting as a best practice for how we should engage with each other. Though this is just a correlation, it is possible that acting positively inspires others to be positive.
|
|
For our classification project at Metis, I chose to look at data from the 2015 Nepal earthquake. While examining these data is important in general, it was also somewhat personal for me: I was in Kolkata at the time of this earthquake and actually felt it. Weeks later, I traveled to a friend's home (where I have been many times) on the border of Nepal.
Using data from DrivenData, I was hoping to differentiate buildings that were slightly damaged from those that were extensively damaged. If damage level could be predicted, it would help Nepal to plan ahead and to mitigate future damage in this earthquake-prone region. Here is a before image of a stupa in Nepal (on the left) and an after image (right). You can see that the earthquake truly was devastating in many locations.
|
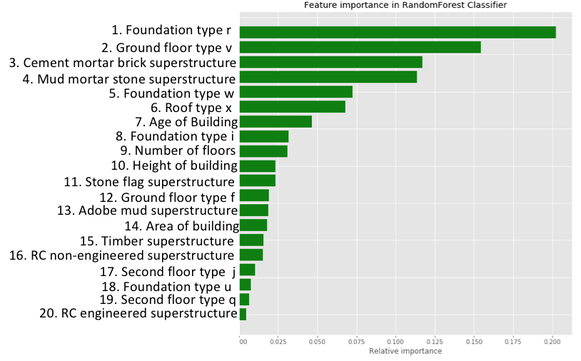


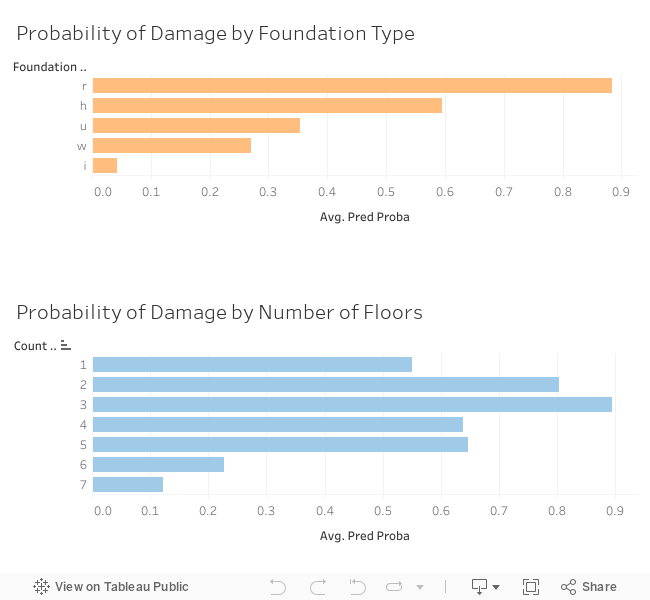
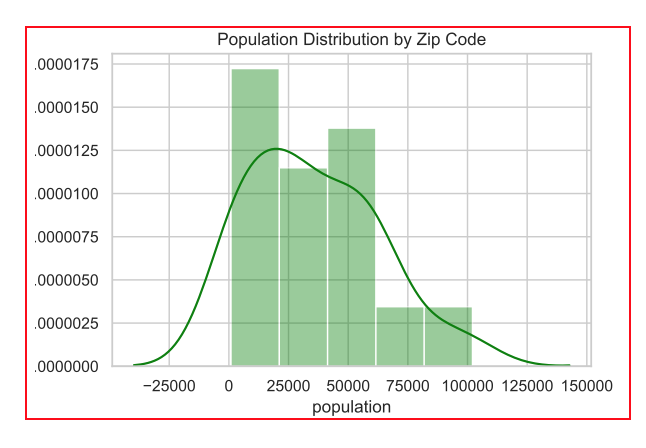
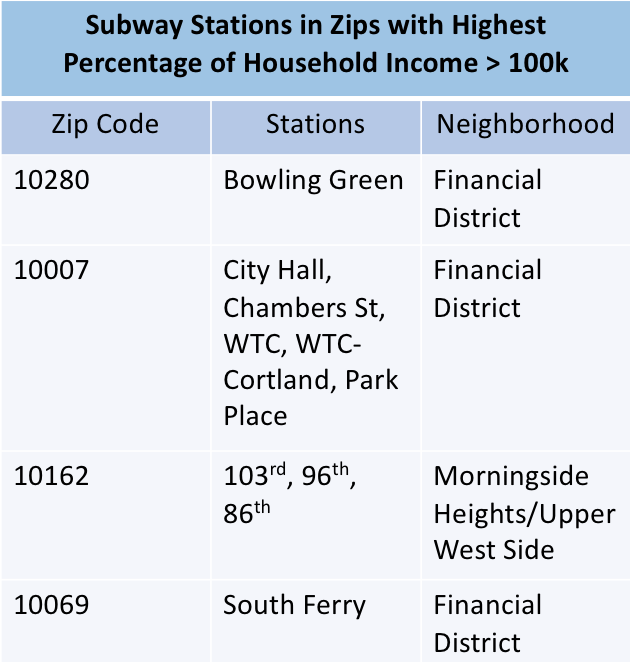
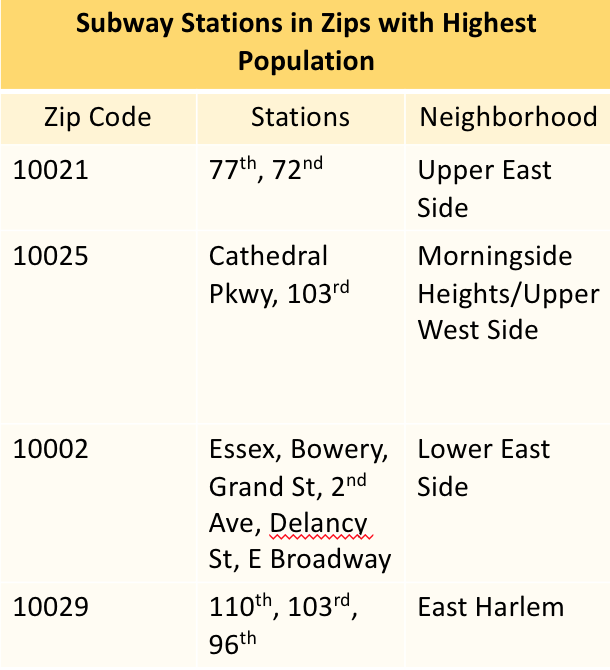
Recommendations |
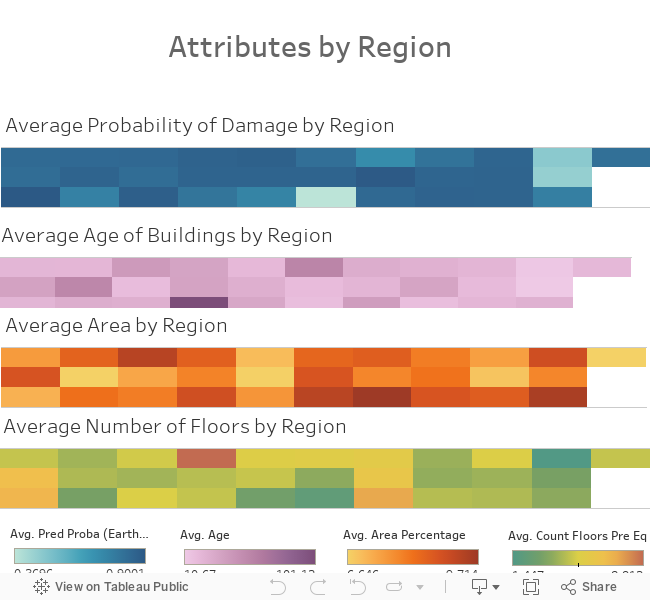





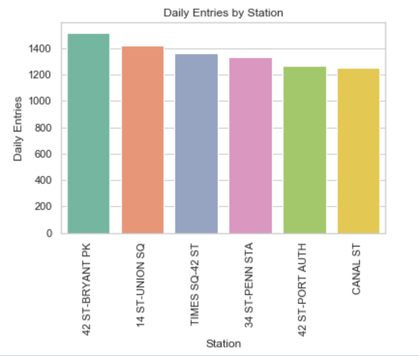
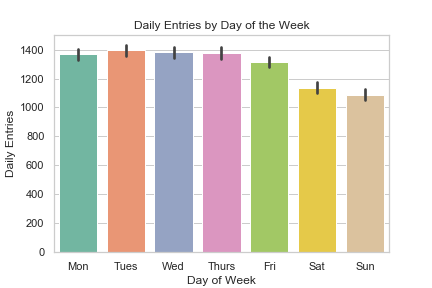
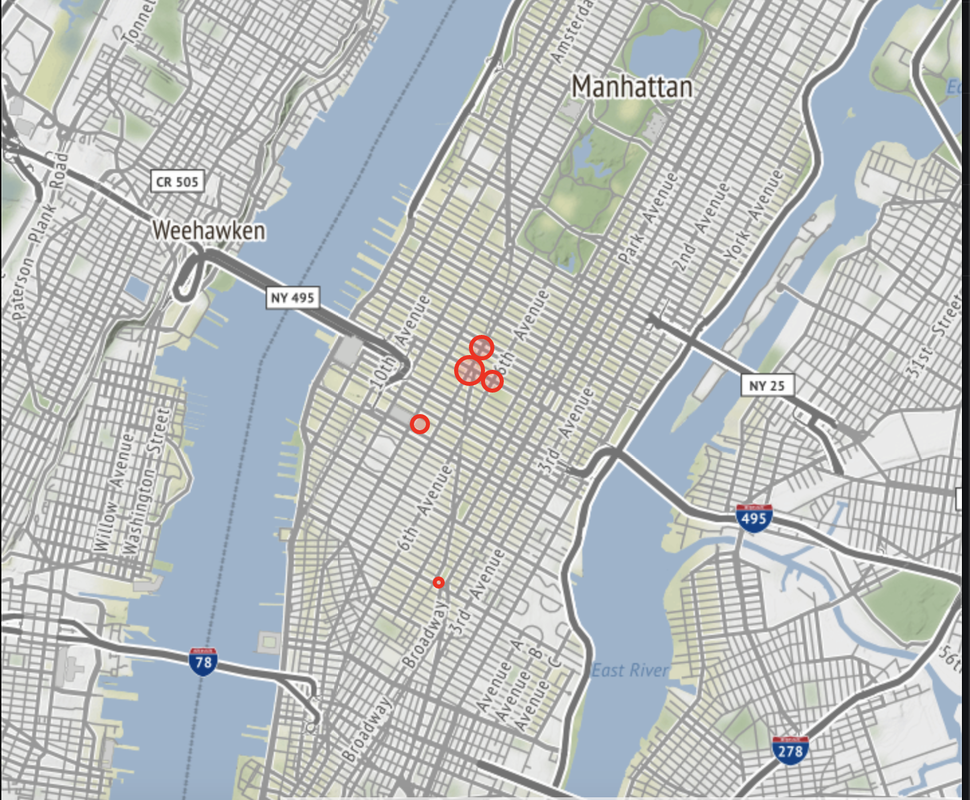 Entries During the Day | 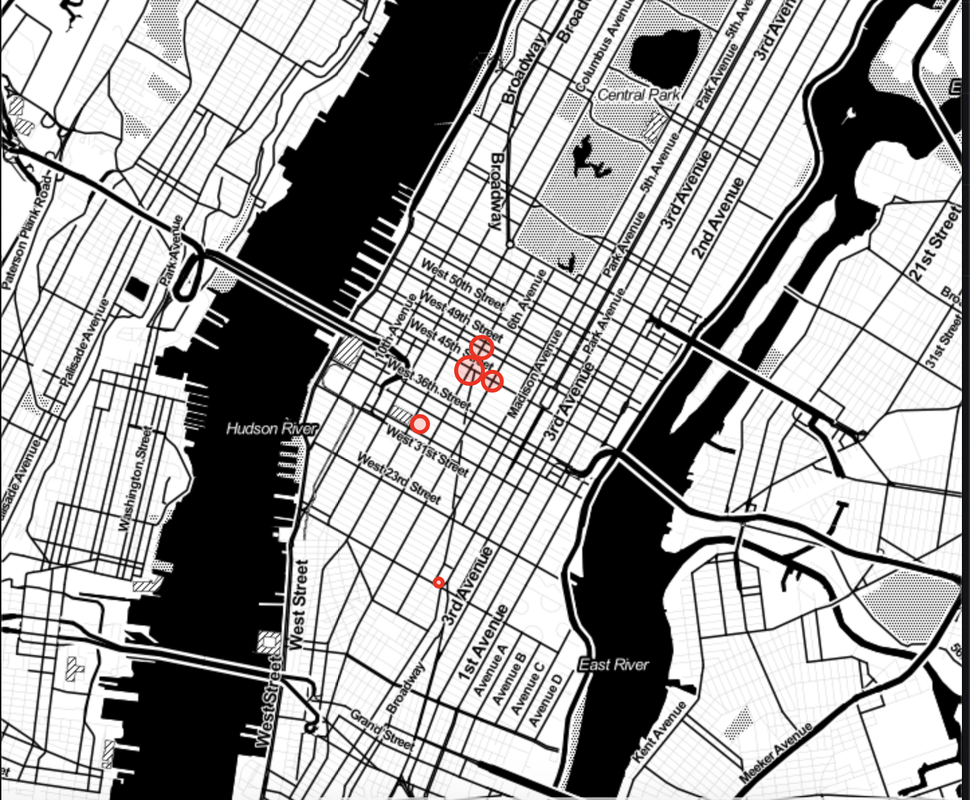 Exits in the Evening |
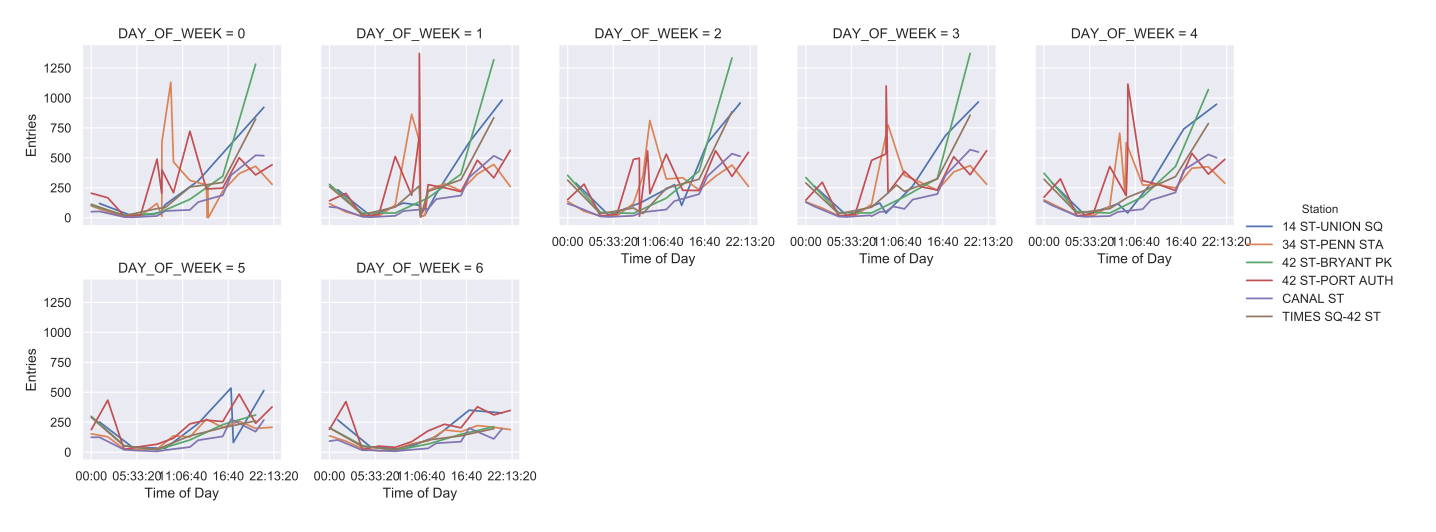
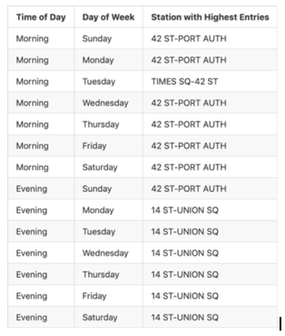
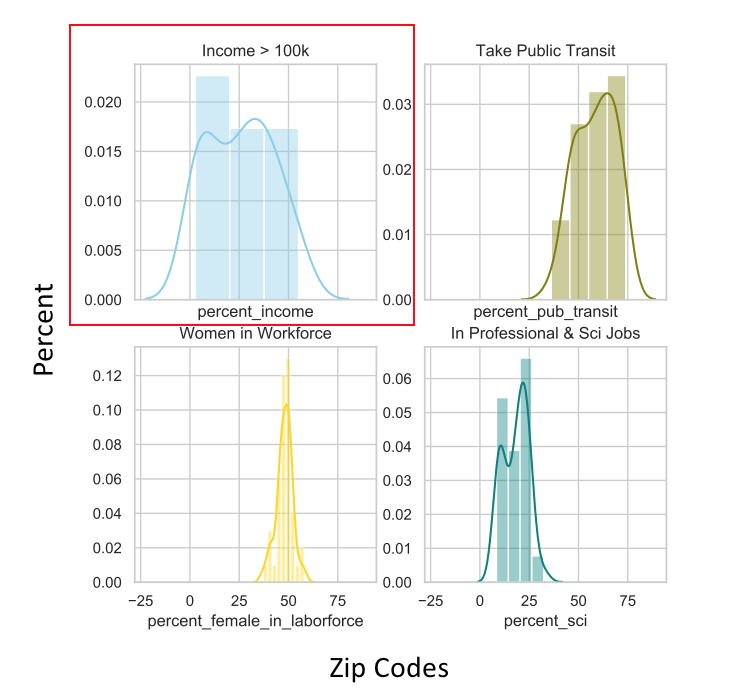 |  |
 |  |
Rita Biagioli
May 2020
April 2020
February 2020
January 2020
March 2019

 RSS Feed
RSS Feed
